- #TechTalk
- Data Science Buzzwords

Data science buzzwords
Max Wiertz
Alles wat met ICT te maken heeft is vergeven van de buzzwords. Zo ook data science. Sommige van deze buzzwords worden vaak in één adem genoemd met data science. Goed dus om de volgende termen te duiden en een plek te geven binnen het vakgebied.
In een reeks artikelen in onze rubriek #techtalk wil ik je graag op een niet-technische, conceptuele manier kennis laten maken met het brede vakgebied data science. De insteek van deze artikelen is het geven van een helikopterview, waarmee ik je wil helpen om dataprofessionals beter te begrijpen en constructieve discussies met hen te voeren. Ik ben ervan overtuigd dat dat de basis legt voor succesvolle dataprojecten. Hopelijk weet ik je ook te inspireren om na te denken over de mogelijkheden van data science binnen je eigen organisatie. Er liggen ook voor jouw organisatie vast en zeker kansen!
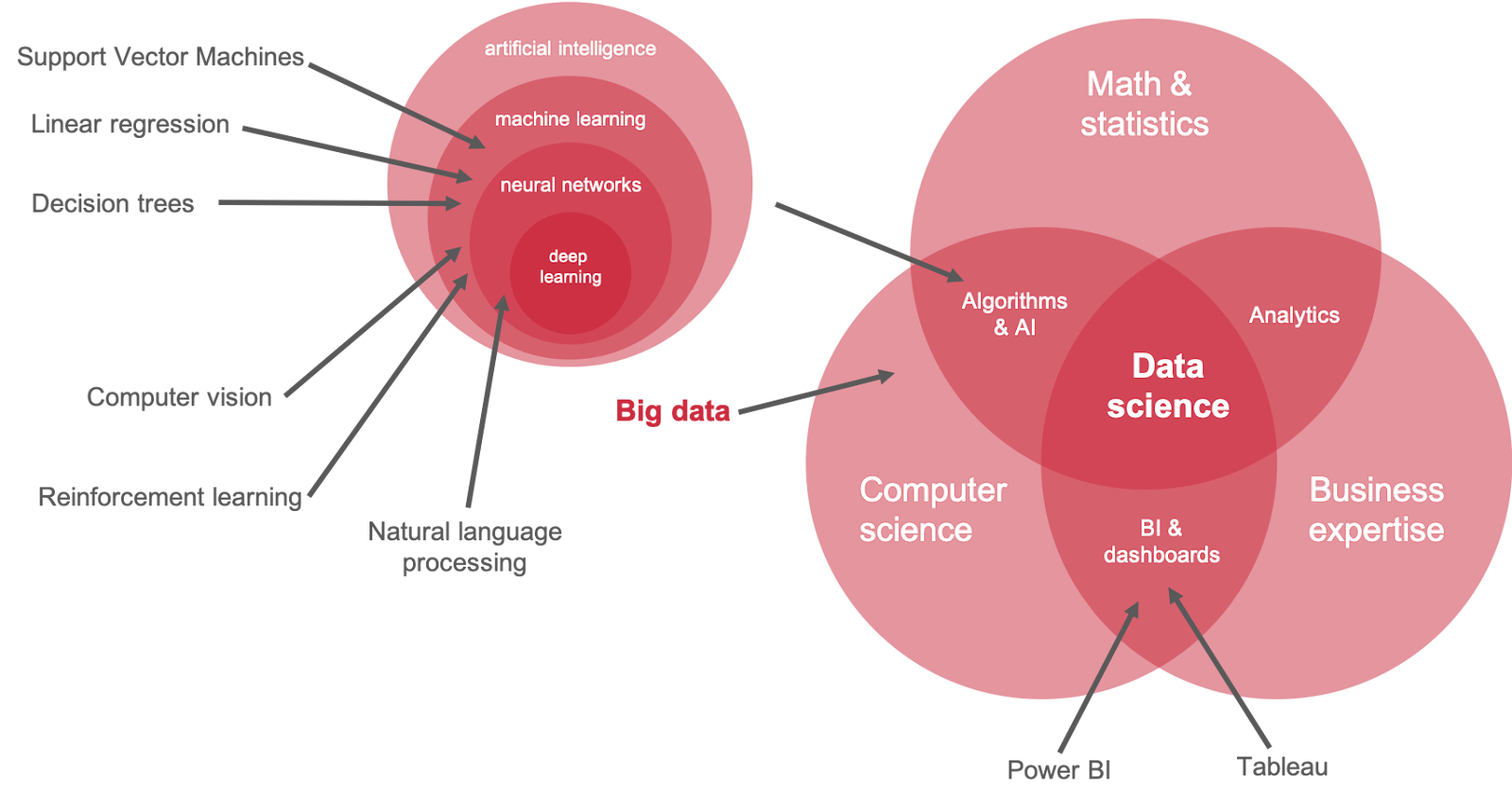
De oorsprong van data science ligt in het kwantitatief analyseren van data met als doel om inzichten en kennis te verwerven. En hoewel deze analytics nog steeds de basis vormen van data science veel meer dan dat. En dit vakgebied, dat in zijn oorsprong al dateert uit de vijftiger jaren van de twintigste eeuw, is sterk beïnvloed door de ontwikkelingen van de afgelopen twintig jaar; de ongeremde groei van hoeveelheden data én de ongekende toename aan rekenkracht van computers.
Samen met deze ontwikkelingen ontstonden er buzzwords en trends die gerelateerd zijn aan, of onderdeel vormen van, wat we nu data science noemen. Sommige daarvan worden zelfs vaak in één adem genoemd met data science. Laat ik de belangrijkste eens toelichten: big data, AI, machine learning, deep learning, neurale netwerken.
Big data
Big data; misschien wel het meest gebruikte buzzword in relatie tot data science, en misschien wel het meest verwarrende ook. Hoewel er geen vaste definitie is wordt in de regel met big data een hoeveelheid data bedoeld die heel groot is en/of weinig gestructureerd is en/of heel snel groeit. Deze data is complex om te analyseren en daar is zodoende speciale, geavanceerde technologie voor nodig; zogenaamde big data tools of platformen (denk bijvoorbeeld aan Hadoop en Spark).
Toch zien we dat de term big data ook vaak op een andere manier gebruikt wordt. Zo noemen mensen die minder diep in de materie zitten alles wat met data science of kunstmatige intelligentie te maken heeft ook wel big data. Het resultaat van een zoekactie op Google naar ‘big data voorbeelden’ bevat bijvoorbeeld allerlei voorbeelden van data science. Daarbij wordt niet noodzakelijkerwijs gebruikt gemaakt van big data zoals hierboven gedefinieerd.
Ook zien we dat big data regelmatig gebruikt wordt om projecten met publieke databronnen aan te duiden. Of die publieke bronnen nu datasets van overheden of autoriteiten zijn (bijvoorbeeld CBS of een gemeente of de EU), of de datasets van online platforms (bijvoorbeeld de feed van Twitter of de product reviews van Amazon of kaarten van Google Maps). Strikt genomen voldoen die datasets aan de definitie van big data, maar niet ieder project dat een dergelijke dataset gebruikt rechtvaardigt ook de noemer big data.
Voor data scientists is het dus vooral van belang om te weten wat er precies bedoeld wordt als de term big data valt. Wanneer er namelijk sprake is van ‘echte’ big data datasets, is de inzet van speciale big data tools nodig. Bovendien is het dan vaak nodig om de vraagstelling anders te benaderen. Sommige analyses van big data kunnen lastiger zijn of meer tijd kosten omwille van de omvang. Iets om rekening mee te houden dus.
AI, machine learning, deep learning en neurale netwerken
Laten we beginnen met AI, dan volgt de rest vanzelf. Hoe dat zit wordt vanzelf duidelijk. AI is de afkorting voor Artificial Intelligence of in het Nederlands: kunstmatige intelligentie (KI). Net als voor data science, geldt voor AI dat het lastig is om een eenduidige, allesomvattende definitie te geven. Vraag tien verschillende experts en je krijgt tien verschillende antwoorden. De beste definitie is wellicht: ‘artificial intelligence bestaat uit machines die intelligent gedrag vertonen’. Daarbij is het goed om machines ruim te zien, de intelligentie zit over het algemeen in de software die in die machines zit. Dat kan een traditionele computer zijn zoals we die kennen, tegenwoordig is dat overigens vaak een cloud service, maar ook een robothond (bijvoorbeeld Sony AIBO) of een slimme luidspreker (Amazon Alexa) of een slimme thermostaat (Google Nest).
Net als data science is AI een containerbegrip. Een verzamelnaam voor alle intelligente niet-biologische systemen. Daar zijn complete boeken over geschreven, we zullen ons hier beperken tot het belangrijkste deelgebied van de kunstmatige intelligentie: machine learning.

Machine learning
We spreken van machine learning (ML) als een computer leert door middel van ‘ervaring’, in tegenstelling tot het volgen van een set voorgeprogrammeerde regels (algoritme). Een computer leert dan met behulp van wiskundige berekeningen zelf om patronen te herkennen en te voorspellen of classificeren. Deze wiskundige berekeningen die een computer helpen leren zijn overigens ook algoritmes. Van deze zelflerende algoritmes kennen we verschillende soorten; met en zonder toezicht.
Lerende algoritmes onder toezicht noemen we supervised machine learning. Daar is een mens actief betrokken bij het leerproces van het algoritme. Meestal door trainingsdata handmatig te labelen. Bepaalde lerende algoritmes zijn in staat om zelfstandig, zonder toezicht, verbanden te herkennen in grote datasets, waarin de inhoud niet gelabeld is. Dat noemen we: unsupervised machine learning.
Een andere soort van machine learning is reinforcement machine learning. Hierbij leert een computer van het zelfstandig doorlopen van miljoenen simulaties, waarbij hij door middel van scoring (als in straffen en belonen), steeds probeert een betere uitkomst te behalen. Deze variant houdt het midden tussen leren onder toezicht en leren zonder toezicht. De scoring is weliswaar op voorhand gespecificeerd door een mens, maar de gebruikte data is niet gelabeld.
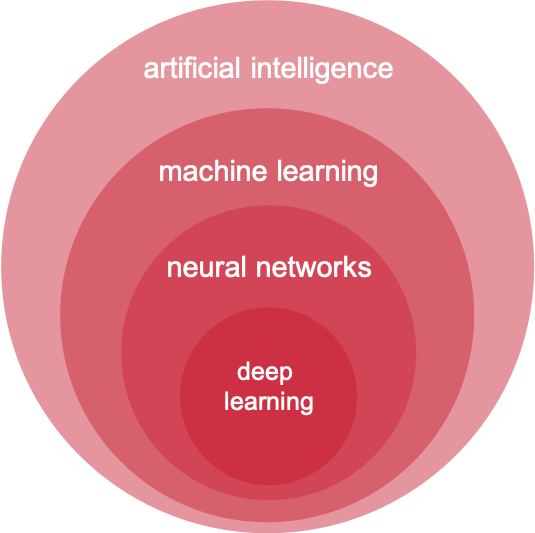
Neurale netwerken
Een bijzondere vorm van machine learning zijn neurale netwerken. Geïnspireerd door het menselijk brein hebben wetenschappers een digitale variant van de zenuwcel (neuron) ontwikkeld; de perceptron. Neurale netwerken bestaan uit lagen van deze perceptrons en beginnen met een laag van één of meerdere invoerwaarden. Perceptrons bevatten elk een eigen rekenkundige formule (algoritme). Die formule past een perceptron toe op ingevoerde data en geeft de uitkomst door aan de volgende laag perceptrons die hier vervolgens weer hun algoritme op loslaten en de uitkomst doorgeven. En zo verder.
Neurale netwerken kunnen supervised en unsupervised leren en zijn met name geschikt voor het analyseren van ongestructureerde data. Bijvoorbeeld geluidsfragmenten, foto’s of video’s. Een neuraal netwerk kan bijvoorbeeld gebruikt worden om te herkennen wat er op een foto staat. Daarvoor moet het netwerk wel getraind zijn met heel veel gelabelde trainingsfoto’s, waarbij aangegeven is wat er op de foto te zien is.
Machine learning waarbij gebruik gemaakt wordt van geavanceerde neurale netwerken die uit veel lagen bestaan, wordt deep learning genoemd.
Voor een data scientist is AI - en in het bijzonder machine learning - in al zijn varianten iets om goed te kennen en beheersen. Binnen het data science vakgebied worden AI en ML immers veelvuldig toegepast.
De belangrijkste buzzwords in relatie tot data science hebben we nu kort toegelicht. In vervolgartikelen zal ik dieper ingaan op de afzonderlijke belangrijke sub-vakgebieden binnen data science: machine learning, artificial intelligence en deep learning.