- #TechTalk
- Machine Learning zo eenvoudig mogelijk uitgelegd

Machine Learning zo eenvoudig mogelijk uitgelegd
Max Wiertz
Machine learning is misschien wel het belangrijkste deelgebied van AI, wat weer een deelgebied van data science is (zie Artificial Intelligence zo eenvoudig mogelijk uitgelegd). Het is in ieder geval het meest tot de verbeelding sprekende deelgebied. We spreken immers van machine learning als een computer niet langer een set voorgeprogrammeerde regels (algoritme) volgt, maar zelfstandig leert door middel van ervaring. Hoe dat werkt probeer ik je in dit artikel op een zo eenvoudig mogelijke en zo niet-technisch mogelijke manier uit te leggen.
In een reeks artikelen in onze rubriek #techtalk wil ik je graag op een niet-technische, conceptuele manier kennis laten maken met het brede vakgebied data science. De insteek van deze artikelen is het geven van een helikopterview, waarmee ik je wil helpen om dataprofessionals beter te begrijpen en constructieve discussies met hen te voeren. Ik hoop dat ik je kan inspireren om na te denken over de mogelijkheden en kansen met data binnen je eigen organisatie.
Hoe werkt het?
We spreken zoals gezegd van machine learning als een computer geen set voorgeprogrammeerde regels (algoritme) volgt, maar leert door middel van ‘ervaring’. Een computer leert dan met behulp van wiskundige berekeningen om zelfstandig patronen te herkennen. Zo kan een computer bijvoorbeeld leren voorspellen of classificeren. Deze wiskundige berekeningen die een computer helpen leren zijn overigens ook algoritmes. Alleen dan geen algoritmes die steeds gevolgd worden bij de uitvoering, maar zelflerende algoritmes die gevolgd worden bij het leren herkennen van patronen. Het resultaat van dit leerproces is een model. Aan de hand van dit model kan een computer vervolgens voorspellingen doen of adviseren. We hebben het dan over predictive of prescriptive analytics. Binnen deze zelflerende algoritmes onderkennen we verschillende soorten; met en zonder toezicht.

Supervised learning
Lerende algoritmes onder toezicht noemen we supervised machine learning. Daar is een mens actief betrokken bij het leerproces van het algoritme. Meestal door trainingsdata handmatig te labelen.
Een bekend en herkenbaar voorbeeld hiervan is een spamfilter; dergelijke software wordt gevoed met een groot aantal e-mails die handmatig gelabeld zijn; spam of geen spam. Aan de hand van deze e-mails herkent het gebruikte algoritme zelf patronen in de mails die als spam worden gezien. Vervolgens kan de spamfilter van iedere binnenkomende mail met grote zekerheid voorspellen of het een gewenste of ongewenste mail is.
Unsupervised learning
Bepaalde lerende algoritmes zijn in staat om zelfstandig, zonder toezicht, verbanden te herkennen in grote datasets waarvan de inhoud niet gelabeld is. Dat noemen we: unsupervised machine learning.
Een herkenbaar voorbeeld hiervan zijn de gepersonaliseerde zoekresultaten van Google. Afhankelijk van de gebruiker en het moment toont Google andere zoekresultaten en advertenties bij dezelfde zoektermen. Door het klik- en zoekgedrag van de gebruiker te analyseren en te vergelijken met het gedrag van andere gebruikers, is de zoekmachine in staat om een specifiek gebruikersprofiel samen te stellen. Zo passen de zoekresultaten beter bij het referentiekader en de belevingswereld van de gebruiker.
Reinforcement learning
Een ander soort van machine learning is reinforcement machine learning. Hierbij leert een computer van het zelfstandig doorlopen van miljoenen simulaties, waarbij hij door middel van scoring (als in straffen en belonen), steeds probeert een betere uitkomst te behalen. Deze variant houdt het midden tussen leren onder toezicht en leren zonder toezicht. De scoring is weliswaar op voorhand gespecificeerd door een mens, maar de gebruikte data is niet gelabeld.
Een duidelijk voorbeeld van reinforcement learning is hoe een humanoïde, op een mens lijkende, robot leert traplopen. Een trede omhoog zonder te vallen betekent bijvoorbeeld een punt erbij, terwijl vallen een strafpunt betekent. Tegenwoordig kunnen humanoïde robots trouwens ongekend goed bewegen, kijk maar eens naar de robot Atlas van Boston Dynamics. Die kan niet alleen lopen, traplopen, een koprol maken en op zijn handen staan, maar ook dansen, zelfs samen met andere robots.
Wat kun je ermee?
Als ik het probeer heel eenvoudig te maken, dan zijn machine learning algoritmes goed in drie verschillende dingen: voorspellen, classificeren en clusteren.
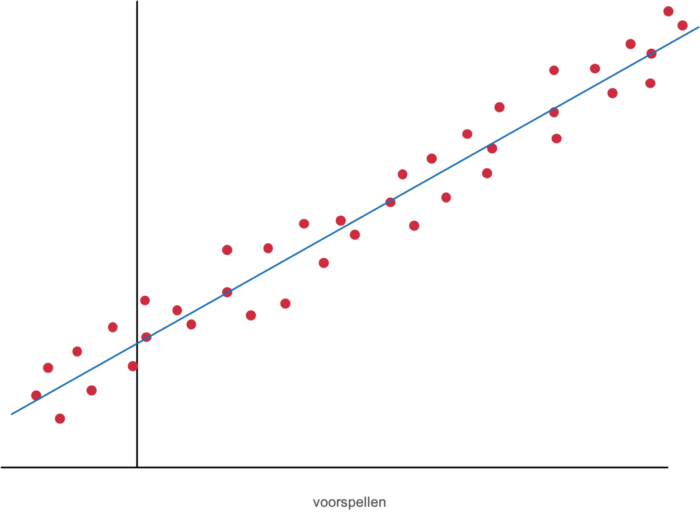
Voorspellen
Aan de hand van historische data kunnen machine learning modellen vaak verrassend goede voorspellingen doen. Denk bijvoorbeeld aan wanneer specifieke onderdelen van een machine in een productieomgeving het beste preventief vervangen kunnen worden om storingen voor te zijn. Of aan het voorspellen van de prijzen van huizen, nog voordat ze gebouwd zijn, aan de hand van onder meer oppervlakte, inhoud, ligging en energielabel.
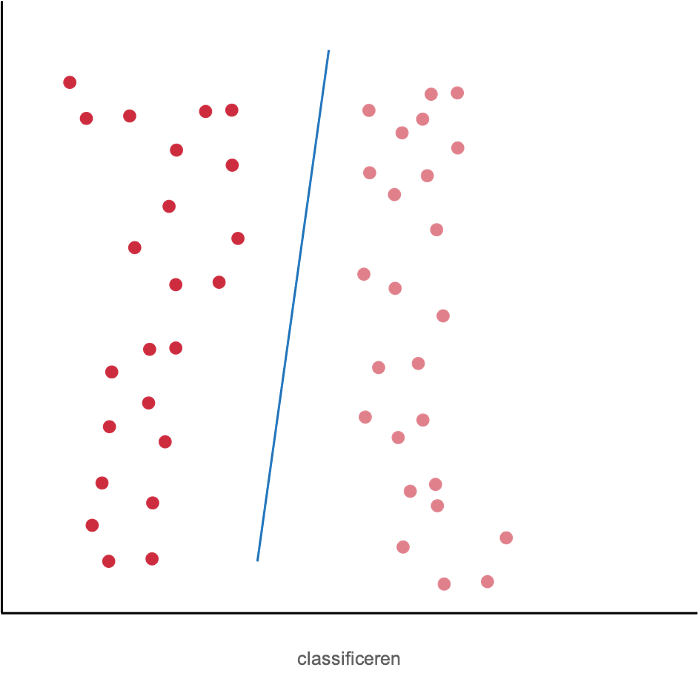
Classificeren
Bij classificeren gaat het om het bepalen of herkennen of iets in een bepaalde categorie valt. Denk aan het eerdergenoemde voorbeeld van het herkennen van spamberichten tussen alle binnenkomende e-mailberichten. Een ander bekend voorbeeld is het door een verzekeringsmaatschappij vroegtijdig identificeren welke klanten met grote waarschijnlijkheid hun verzekering gaan opzeggen. Dit wordt ook wel churn voorspellen genoemd.
Clusteren
Als algoritmes zelfstandig in grote datasets overeenkomsten herkennen die worden gegroepeerd en onderverdeeld op basis van kenmerken, dan noemen we dat clusteren. Zo kunnen onderlinge dwarsverbanden worden gevonden in de data. Met behulp van clustering kan een webshop bijvoorbeeld haar klanten segmenteren en op basis daarvan klantprofielen vaststellen en deze meer relevante aanbiedingen op maat doen tijdens het afrekenen.

Neurale netwerken en deep learning
Tot slot vind ik het, gezien de grote aandacht hiervoor, relevant om nog kort een bijzondere vorm van machine learning nader te benoemen: neurale netwerken. Geïnspireerd door het menselijk brein hebben wetenschappers een digitale variant van de zenuwcel (neuron) ontwikkeld; de perceptron. Neurale netwerken bestaan uit lagen van deze perceptrons en beginnen met een laag van één of meerdere invoerwaarden. Perceptrons bevatten elk een eigen rekenkundige formule (algoritme). Die formule past een perceptron toe op ingevoerde data en geeft de uitkomst door aan de volgende laag perceptrons die hier vervolgens weer hun algoritme op loslaten en de uitkomst doorgeven. En zo verder.
Neurale netwerken kunnen supervised en unsupervised leren en zijn met name geschikt voor het analyseren van ongestructureerde data. Bijvoorbeeld geluidsfragmenten, foto’s of video’s. Een neuraal netwerk kan bijvoorbeeld gebruikt worden om te herkennen wat er op een foto staat. Daarvoor moet het netwerk wel getraind zijn met heel veel gelabelde trainingsfoto’s, waarbij aangegeven is wat er op de foto te zien is.
Machine learning waarbij gebruik gemaakt wordt van geavanceerde neurale netwerken die uit veel lagen bestaan, wordt deep learning genoemd.
